Storage directory structure
David Nortes Martinez
directory_structure_en.RmdIntroduction
The external databases that floodam.data allows you to
download are regularly updated. Their external storage is organized by
version, vintage and geographical extent, depending on the supplier or
even the database.
The floodam.data library is designed so that the user
doesn’t have to worry about organizing this information;
floodam.data takes care of everything, from downloading to
reformulation and storage. To achieve this, the library workflow defines
and uses a very specific directory structure that serves a dual
purpose:
- Organize the information by database, vintage and geographical location.
- Manage file and folder names programmatically.
Data organization during the download stage
When databases are downloaded using the
functionsdownload_*() the workflow generates a two level
directory structure:
- First level: database name
- Second level: vintage
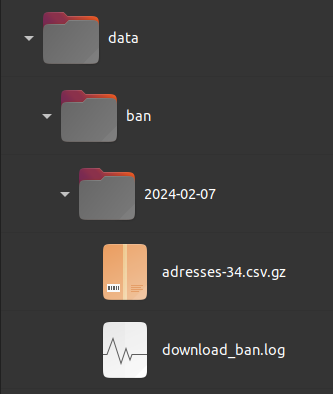
So, if, for example we want to process the BAN database (Base
Adresse nationale), the function download_ban()
creates the following directory structure in the folder provided to the
destination parameter (e.g. data).
library(floodam.data)
output = "data"
download_ban(
destination = output,
department = 34
)
Data organization during the adaptation stage
Functions in the adapt_*() family expect this directory
structure, from which they can acquire key information about data types
and their vintage. They will replicate the structure to store their own
results.
Continuing with our example, we now use the adapt_ban()
function to process the database we have uploaded to the data
folder, into a new folder called adapted.
adapt_ban(
origin = file.path(output, "ban", "2024-01-31"),
destination = file.path(output, "adapted")
)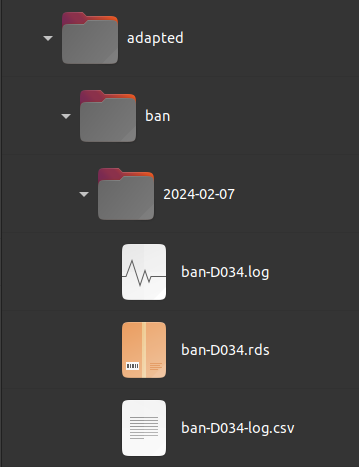
As we can see, the adapt_ban() function generates, on
the one hand, the same directory structure than
download_ban() and, on the other hand, it uses the folder
name ban to name the output file in combination with the
geographical reference (D034).